ByteLoom: Weaving Geometry-Consistent Human-Object Interactions through Progressive Curriculum Learning
Bangya Liu1†, Xinyu Gong2, Zelin Zhao3†, Ziyang Song4†, Yulei Lu2
Suhui Wu2, Jun Zhang2, Suman Banerjee1, Hao Zhang2
1University of Wisconsin-Madison, 2ByteDance, 3Georgia Institute of Technology
4The Hong Kong Polytechnic University, †Project during internship in ByteDance





Human-object interaction (HOI) video generation has garnered increasing attention due to its promising applications in digital humans, e-commerce, advertising, and robotics imitation learning. However, existing methods face two critical limitations: (1) a lack of effective mechanisms to inject multi-view information of the object into the model, leading to poor cross-view consistency, and (2) heavy reliance on fine-grained hand mesh annotations for modeling interaction occlusions. To address these challenges, we introduce ByteLoom, a Diffusion Transformer (DiT)-based framework that generates realistic HOI videos with geometrically consistent object illustration, using simplified human conditioning and 3D object inputs. We first propose an RCM-cache mechanism that leverages Relative Coordinate Maps (RCM) as a universal representation to maintain object's geometry consistency and precisely control 6-DoF object transformations in the meantime. To compensate HOI dataset scarcity and leverage existing datasets, we further design a training curriculum that enhances model capabilities in a progressive style and relaxes the demand of hand mesh. Extensive experiments demonstrate that our method faithfully preserves human identity and the object's multi-view geometry, while maintaining smooth motion and object manipulation.
Method Overview
RCM-Cache Mechanism
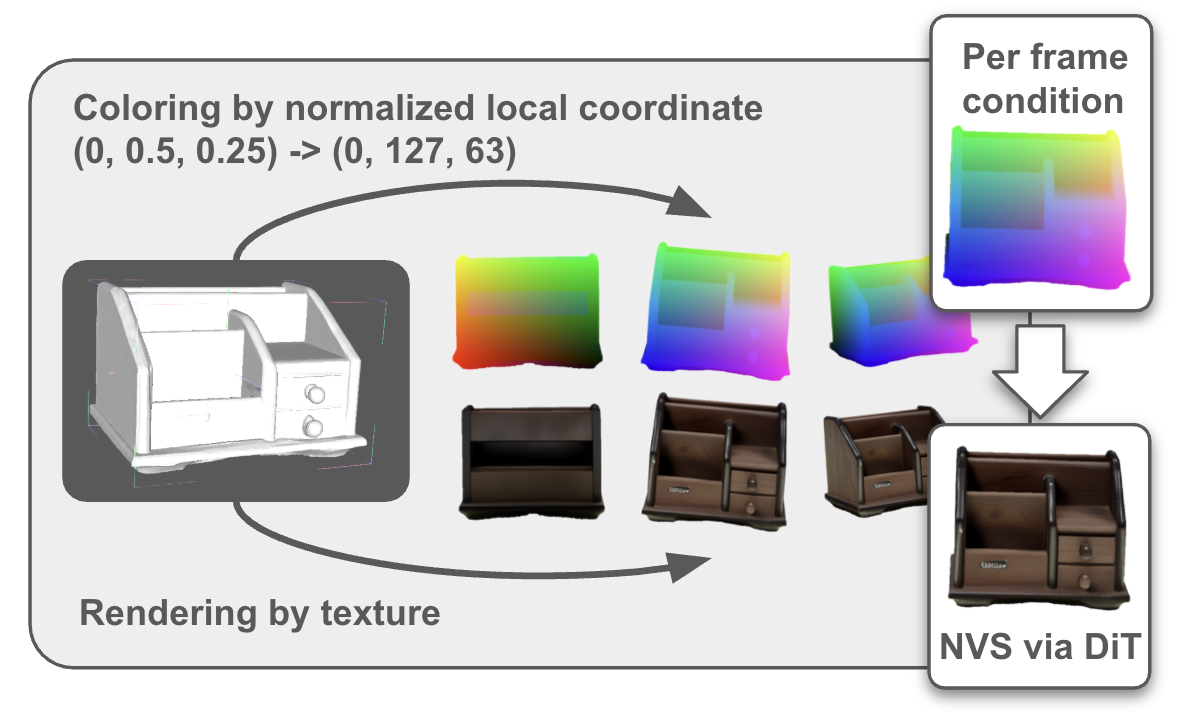
We introduce Relative Coordinate Maps (RCM) for object conditioning, inspired by 3D asset generation leveraging RCM to enforces correspondence between textured meshes and input images. RCM renders objects using local vertex coordinates, ensuring pixels from the same 3D vertex maintain consistent coloring across views.
Model Training Pipeline
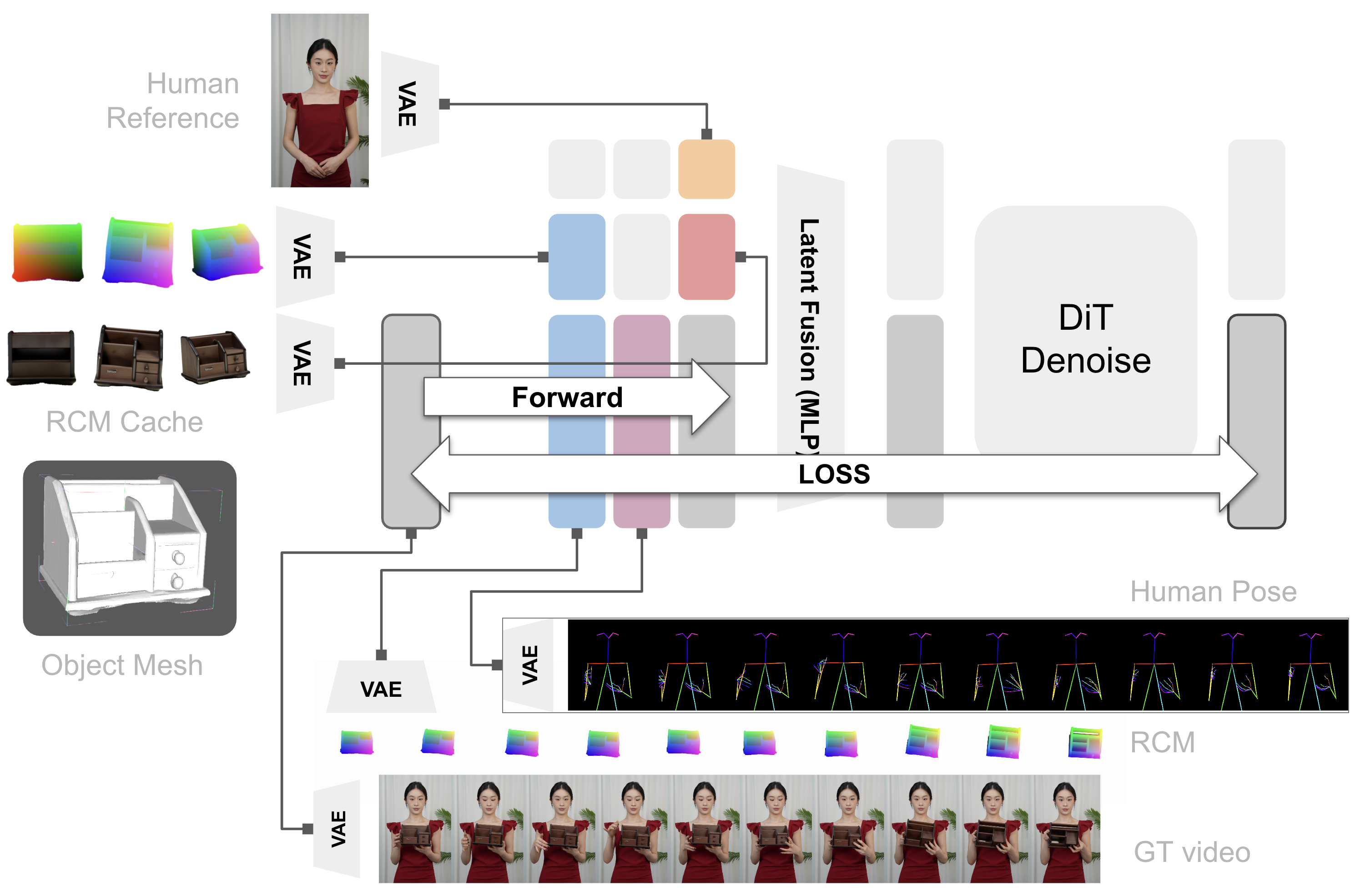
we plainly concat and inject all conditions through the input latent fusion, where we let the self-attention to learn the relation ship between those input conditions and the final output, as long as we have provided all required information.
Training Data
Data Composition of Curriculum Learning

Through three-stage curriculum learning, the model progressively acquires animation capabilities. In Curriculum I, it learns human pose conditioning from animatable human datasets. Curriculum II introduces hand-object occlusion through interaction datasets while developing geometric consistency via object-oriented videos. Finally, Curriculum III achieves photorealistic human-object interaction using a carefully curated high-quality dataset.
Mani4D Data Curation Process
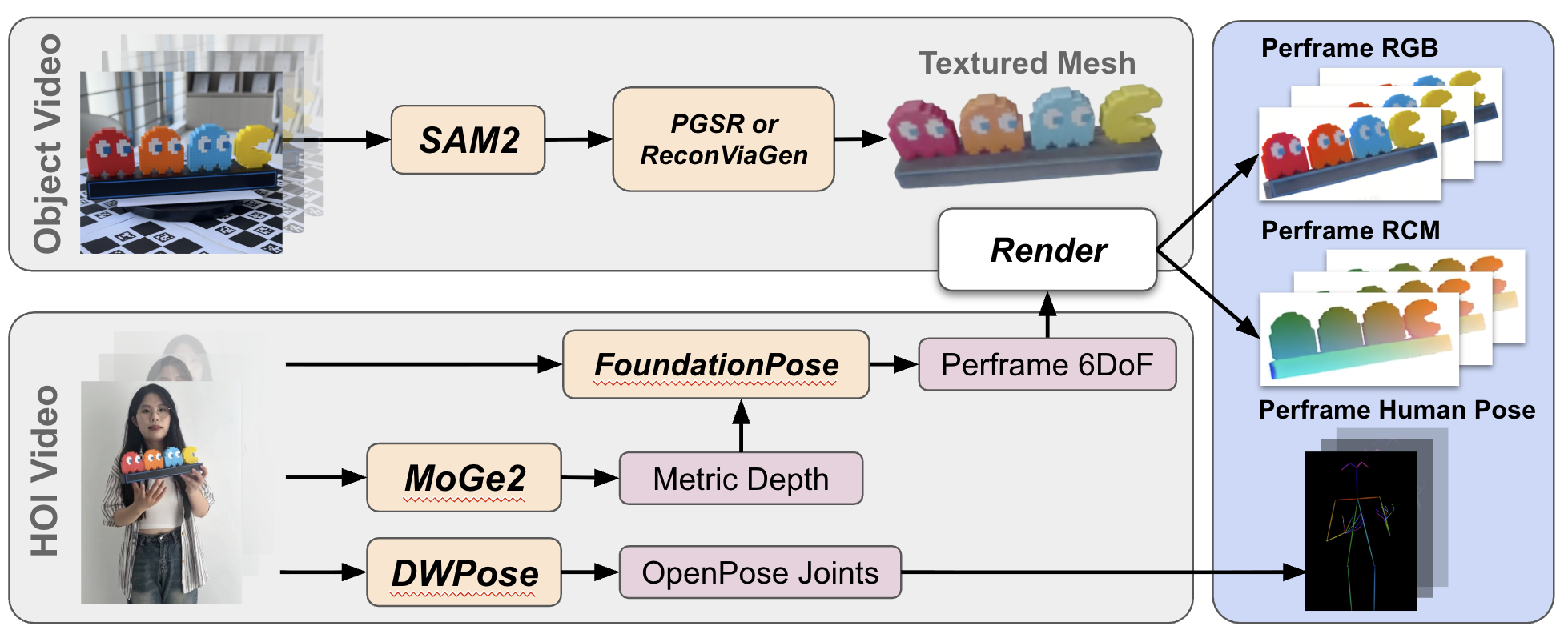
We integrate state-of-the-art models for robust multi-modal conditioning extraction: Human pose: Extract per-frame poses using DWPose, filtering low-confidence joints. Object mesh: For object-focused videos, use optimization methods (PGSR, 2DGS) or diffusion models (ReconViaGen). For occluded objects, apply Amodal3R with SAM2 segmentation. Object 6DoF pose: Extract metric depth using MoGe2 with camera intrinsics from EXIF tags, align across frames via RANSAC for consistency. Calibrate mesh-depth scale discrepancies, then feed RGB, depth, and textured mesh to FoundationPose for robust 6DoF estimation.
Quantitative Results
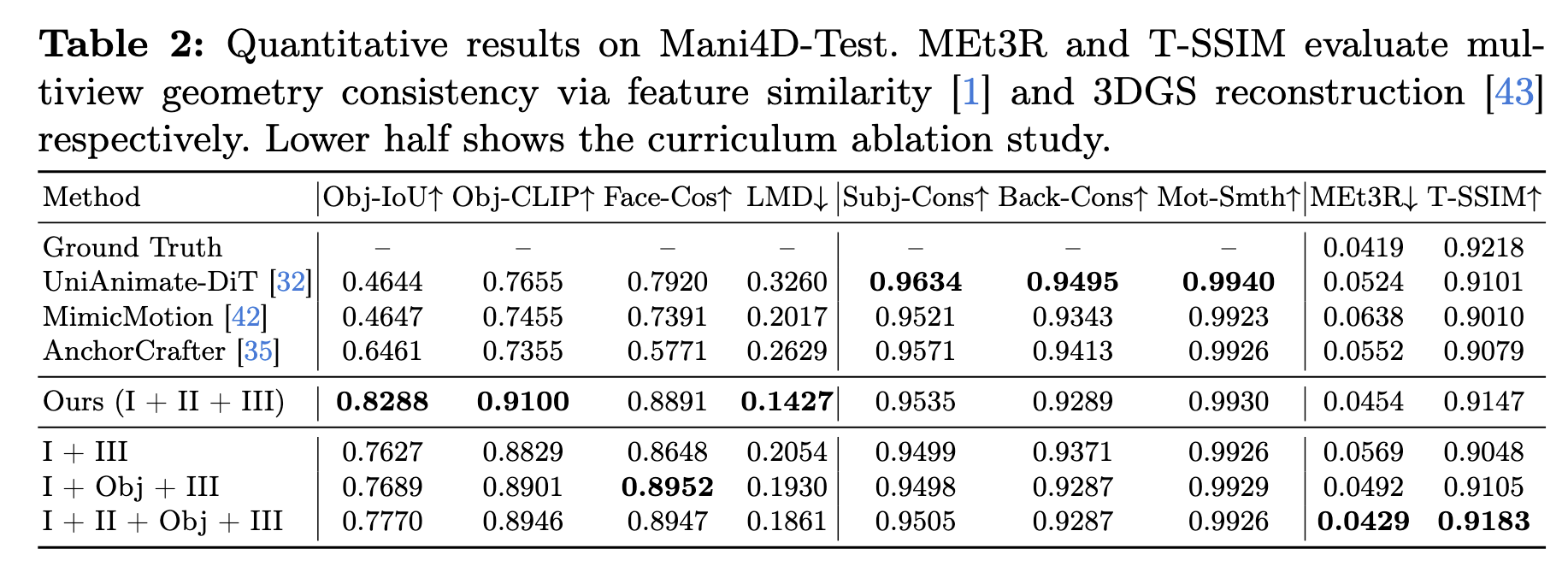
We qualitatively compared our method against prior work, demonstrating consistently superior results. MimicMotion fails to preserve reference object geometry, producing distorted shapes. AnchorCrafter severely overfits and doesn't generalize to unseen references. UniAnimate-DiT generates plausible videos but cannot faithfully render novel viewpoints due to inadequate multi-view information injection.